BGP: различия между версиями
м (→Сообщения) |
|||
| (не показано 15 промежуточных версий этого же участника) | |||
| Строка 1: | Строка 1: | ||
{{#description2:BGP в Juniper. Состояния соседства BGP. Сообщения. Атрибуты BGP. Local preference. AS Path. Next-hop. Communities. Механизмы управления трафиком. Multipath. Multihop. Route Reflection. Confederations. Route damping. Blackhole. }} | |||
BGP - протокол маршрутизации между AS. Path-vector protocol. | BGP - протокол маршрутизации между AS. Path-vector protocol. | ||
| Строка 11: | Строка 12: | ||
Для установления соседства используется TCP:179. | Для установления соседства используется TCP:179. | ||
*'''Idle''': all incoming connections - refused. Инициализация BGP ресурсов и подготовка к установлению TCP. Если роутер завис в состоянии Idle - проверить наличие маршрута к соседу. | *'''Idle''': all incoming connections - refused. Инициализация BGP ресурсов и подготовка к установлению TCP. Если роутер завис в состоянии Idle - проверить наличие маршрута к соседу. | ||
*'''Connect''': процесс установления TCP сессии. Роутер слушает TCP 179. Если сессия установилась, то роутер отправляет Open message и переходит в | *'''Connect''': процесс установления TCP сессии. Роутер слушает TCP 179. Если сессия установилась, то роутер отправляет Open message и переходит в OpenSent состояние. Если TCP не установилась, то роутер переходит в Active состояние и запускает заново ConnectRetryTimer. | ||
*'''Active''': local router становится активным инициатором TCP-сессии. В состоянии Active - когда ответил | *'''Active''': local router становится активным инициатором TCP-сессии. В состоянии Active - когда ответил на прилетевший TCP. Если роутер завис в Active, проверяем: связность, прохождение по tcp:179, корректность настройки BGP с двух сторон. | ||
*'''OpenSent''': Open отправлен локальным роутером и роутер ждет ответа (Open) от соседа. | *'''OpenSent''': Open отправлен локальным роутером и роутер ждет ответа (Open) от соседа. | ||
*'''OpenConfirm''': Open сообщение получено от соседа и роутер ждет Keepalive или Notification message. Если от соседа не приходит keepalive до истечения hold timer, то роутер генерирует Notification message, с инфо, что hold timer expired и переведет сессию в Idle. Если keepalive получен, то соседство переходит в Established state. | *'''OpenConfirm''': Open сообщение получено от соседа и роутер ждет Keepalive или Notification message. Если от соседа не приходит keepalive до истечения hold timer, то роутер генерирует Notification message, с инфо, что hold timer expired и переведет сессию в Idle. Если keepalive получен, то соседство переходит в Established state. | ||
| Строка 18: | Строка 19: | ||
Hold timer может быть разным у пиров. При установлении сессии будет выбран наименьший. | Hold timer может быть разным у пиров. При установлении сессии будет выбран наименьший. | ||
==Tips== | |||
Если сессия установилась в Established, но через какое-то время перешла в Idle по Hold timer expared (скорее всего через 90sec = 3*keepalive), то первым делом проверьте MTU на канале между роутерами. | |||
Если MTU где-то по пути зарезан/не соответствует MTU на интерфейсах bgp-пиров, можно либо решить вопрос с MTU на найденном проблемном участке, либо можно установить для сессии вручную размер mss (maximum segment size): | |||
set protocols bgp group clients neighbor 1.1.1.1 tcp-mss 1470 | |||
Признаки подобной проблемы в логах: | |||
Jan 1 00:18:18.553797 bgp_io_mgmt_cb:1777: NOTIFICATION sent to 1.1.1.1 (Internal AS 64777): code 4 (Hold Timer Expired Error), Reason: holdtime expired for 1.1.1.1 (Internal AS 64777), socket buffer sndcc: 0 rcvcc: 0 TCP state: 4, snd_una: 733415251 snd_nxt: 733415251 snd_wnd: 16384 rcv_nxt: 4248562819 rcv_adv: 4248579203, hold timer 90s, hold timer remain 0s, last sent 6s, TCP port (local 52746, remote 179) | |||
Jan 1 00:18:18.553889 BGP SEND message type 3 (Notification) length 21 | |||
Jan 1 00:18:18.553901 BGP SEND Notification code 4 (Hold Timer Expired Error) subcode 0 (unused) | |||
Jan 1 00:18:18.554014 bgp_peer_close_and_restart: closing peer 1.1.1.1 (Internal AS 64777), state is 7 (Established) event HoldTime | |||
Jan 1 00:18:18.554064 RPD_BGP_NEIGHBOR_STATE_CHANGED: BGP peer 1.1.1.1 (Internal AS 64777) changed state from Established to Idle (event HoldTime) (instance master) | |||
=Сообщения= | =Сообщения= | ||
| Строка 38: | Строка 52: | ||
:*'''marker''' - 16 октетов, установлены в "1". Обозначает, что это bgp-пакет | :*'''marker''' - 16 октетов, установлены в "1". Обозначает, что это bgp-пакет | ||
:*'''lenght''' - размер пакета (16bit) | :*'''lenght''' - размер пакета (16bit) | ||
:*'''type''' - тип сообщения | :*'''type''' - тип сообщения | ||
:** 1 - OPEN | :** 1 - OPEN | ||
| Строка 47: | Строка 60: | ||
'''Типы пакетов:''' | '''Типы пакетов:''' | ||
*'''Open''' (type 1) - отправляется только на стадии установления соседства. Содержит параметры BGP соседа: AS, auth-type (+ ключ, если есть аутентификация). | |||
*'''Open''' (type 1) - отправляется только на стадии установления соседства. Содержит параметры BGP соседа: AS | *'''Update''' (type 2) - передает info о добавлении или удалении маршрутов между соседями. Update содержит в себе Path, его атрибуты и вложенные префиксы, у которых эти атрибуты одинаковые. Не отправляются по таймеру, приходят, только когда изменился сам префикс, его атрибуты или BGP-сессия. В зависимости от policy, на локальном роутере, часть routing info может быть отброшена и помещена в hidden. | ||
*'''Update''' (type 2) - передает info о добавлении или удалении маршрутов между соседями. Update содержит в себе Path, его атрибуты и вложенные префиксы, у которых эти атрибуты одинаковые. Не отправляются по таймеру, приходят, только когда изменился сам префикс, его атрибуты или BGP-сессия.В зависимости от policy, на локальном роутере, часть routing info может быть отброшена и помещена в hidden. | |||
*'''Notification''' (type 3) - в случае если что-то пошло не так: не прошел keepalive или update, пришла не поддерживаемая опция, ... Существуют стандартизированные коды ошибок (operation code | opcode). Пакет состоит из header + opcode+subcode + data (описание ошибки - для диагностики). | *'''Notification''' (type 3) - в случае если что-то пошло не так: не прошел keepalive или update, пришла не поддерживаемая опция, ... Существуют стандартизированные коды ошибок (operation code | opcode). Пакет состоит из header + opcode+subcode + data (описание ошибки - для диагностики). | ||
*'''Keepalive''' (type 4)- для удостоверения, что с соседством все ok. Отправляется каждые 30 sec. По дефолту hold-timer = 3 * keepalive = 90sec - время, после которого соседи рушат соседство (если в это время не пролетело ни одного keepalive). Можно выставить holdtimer = 0. Если у одного соседа = 0, у другого нет, то будет согласовано ненулевое значение holdtimer для сессии. | *'''Keepalive''' (type 4)- для удостоверения, что с соседством все ok. Отправляется каждые 30 sec. По дефолту hold-timer = 3 * keepalive = 90sec - время, после которого соседи рушат соседство (если в это время не пролетело ни одного keepalive). Можно выставить holdtimer = 0. Если у одного соседа = 0, у другого нет, то будет согласовано ненулевое значение holdtimer для сессии. | ||
{{note|text= | {{note|text=keepalive message = BGP header без payload}} | ||
*'''Refresh''' - soft clearing BGP сессии. | *'''Refresh''' - soft clearing BGP сессии. | ||
| Строка 78: | Строка 89: | ||
=Атрибуты (BGP attributes)= | =Атрибуты (BGP attributes)= | ||
Включаются в Update сообщения и описывают BGP префиксы. Атрибуты используются для выбора активного пути. | Включаются в Update сообщения и описывают BGP префиксы. Атрибуты используются для выбора активного пути. | ||
Атрибуты, при выборе best, считаются лучшими с наименьшими значением | |||
Это правило касается всех атрибутов, кроме Local Preference | |||
Атрибуты пути разделены на 4 категории: | Атрибуты пути разделены на 4 категории: | ||
| Строка 233: | Строка 246: | ||
==Multi exit discriminator (MED)== | ==Multi exit discriminator (MED)== | ||
'''✔️Optional Non-transitive''' | |||
* Используется для информирования eBGP-соседей о том, какой путь в автономную систему более предпочтительный. | * Используется для информирования eBGP-соседей о том, какой путь в автономную систему более предпочтительный. | ||
* Атрибут передается между автономными системами, но в Junos передается только EBGP пиру и не распространяется дальше по AS. | * Атрибут передается между автономными системами, но в Junos передается только EBGP пиру и не распространяется дальше по AS. | ||
| Строка 261: | Строка 276: | ||
local-as 200 | local-as 200 | ||
neighbor 1.1.1.1 metric-out 50 <= определенное значение | neighbor 1.1.1.1 metric-out 50 <= определенное значение | ||
neighbor 2.2.2.2 metric-out igp <= | neighbor 2.2.2.2 metric-out igp <= текущая IGP метрика | ||
neighbor 3.3.3.3 metric-out minimum-igp <= | neighbor 3.3.3.3 metric-out minimum-igp <= минимальная IGP мтерика, когда-либо изученная | ||
neighbor 4.4.4.4 metric-out igp 5 <= | neighbor 4.4.4.4 metric-out igp 5 <= добавить или вычесть из IGP метрики | ||
MED также можно назначить аналогичным образом через policy: | MED также можно назначить аналогичным образом через policy: | ||
| Строка 290: | Строка 305: | ||
* Не передается в обновлениях. | * Не передается в обновлениях. | ||
* Чем больше значение атрибута, тем более предпочтителен путь выхода. | * Чем больше значение атрибута, тем более предпочтителен путь выхода. | ||
=Механизмы управления трафиком= | =Механизмы управления трафиком= | ||
| Строка 326: | Строка 337: | ||
Дефолтное поведение для EBGP маршрутов может быть изменено: '''path-selection external-router-id'''. При включении этой функции для роутера выбор активного EBGP маршрута от разных роутеров будет делаться по наименьшему router-id. | Дефолтное поведение для EBGP маршрутов может быть изменено: '''path-selection external-router-id'''. При включении этой функции для роутера выбор активного EBGP маршрута от разных роутеров будет делаться по наименьшему router-id. | ||
*Route Preference (Admin distance) - не передается по | *Route Preference (Admin distance) - не передается по ibgp, ebgp. Может только навешиваться через import-policy или в настройках bgp на любом уровне иерархии. | ||
=Multipath= | =Multipath= | ||
| Строка 898: | Строка 909: | ||
Сильно нагружает CPU RE, поэтому с ним сильно перебарщивать не стоит. | Сильно нагружает CPU RE, поэтому с ним сильно перебарщивать не стоит. | ||
minimum-interval - минимальный интервал получения и отправления "hello" BFD. То есть это интервал с которым локальный роутер отправляет hello и интервал, с которым локальный роутер ждет ответа на свой hello. Также в конфиге можно отдельно задать transmit и receive minimum interval. | Хосты устанавливают сессию и обмениваются hello. | ||
Если перестали приходить hello, то BFD дает знать протоколу, что пропала связность между хостами. | |||
*minimum-interval - минимальный интервал получения и отправления "hello" BFD. То есть это интервал с которым локальный роутер отправляет hello и интервал, с которым локальный роутер ждет ответа на свой hello. Также в конфиге можно отдельно задать transmit и receive minimum interval. | |||
* multiplier - значение кол-ва пропущенных hello. | |||
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection minimum-interval 500 ''[transmit+receive]'' | |||
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection multiplier 4 | |||
или | |||
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection minimum-receive-interval 500 ''[receive]'' | |||
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection transmit-interval minimum-interval 500 ''[transmit]'' | |||
BFD + graceful restart - не рекомендуется. | BFD + graceful restart - не рекомендуется. | ||
| Строка 907: | Строка 930: | ||
для очень больших сетей с большим кол-вом bfd сессий - не ниже 300мс | для очень больших сетей с большим кол-вом bfd сессий - не ниже 300мс | ||
Если значения таймеров у пиров не совпадают, то BFD использует наибольшее значение (используется режим adaptive-mode). | |||
Это поведение по умолчанию можно выключить: no-adaptation. | |||
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection no-adaptation | |||
'''Проверка:''' | |||
> show bfd session extensive | |||
=IPv6= | =IPv6= | ||
| Строка 944: | Строка 975: | ||
Либо использовать отдельные lo, который будет выступать в роли router-id для сессии. | Либо использовать отдельные lo, который будет выступать в роли router-id для сессии. | ||
*На link-local адресах | *На link-local адресах | ||
=Дополнительная информация= | |||
*[[OSPF]] | |||
*[[IS-IS]] | |||
*[[L3VPN]] | |||
Текущая версия на 08:08, 14 сентября 2022
BGP - протокол маршрутизации между AS. Path-vector protocol.
IBGP - соседство внутри AS. Соседство строится обычно на Lo адресах.
EBGP - соседство между разными AS. Соседство строится на p2p адресах.
Поддерживает аутентификацию: MD5. Можно настроить key-chain, с указанием когда какой ключ использовать. Аутентификация применяется на разных уровнях protocols bgp.
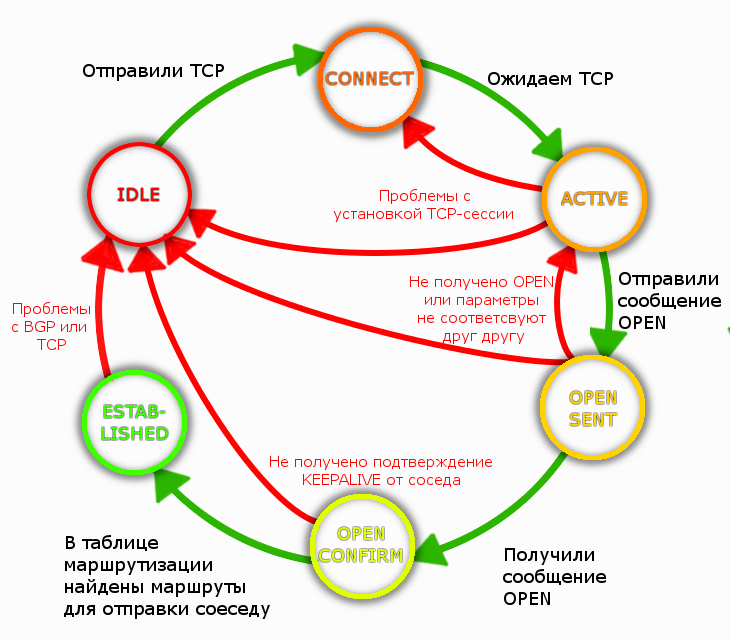
Состояния соседства
http://habrastorage.org/getpro/habr/post_images/442/780/549/442780549c2f45cdda10773121b2800d.png
{kind=link}
Для установления соседства используется TCP:179.
- Idle: all incoming connections - refused. Инициализация BGP ресурсов и подготовка к установлению TCP. Если роутер завис в состоянии Idle - проверить наличие маршрута к соседу.
- Connect: процесс установления TCP сессии. Роутер слушает TCP 179. Если сессия установилась, то роутер отправляет Open message и переходит в OpenSent состояние. Если TCP не установилась, то роутер переходит в Active состояние и запускает заново ConnectRetryTimer.
- Active: local router становится активным инициатором TCP-сессии. В состоянии Active - когда ответил на прилетевший TCP. Если роутер завис в Active, проверяем: связность, прохождение по tcp:179, корректность настройки BGP с двух сторон.
- OpenSent: Open отправлен локальным роутером и роутер ждет ответа (Open) от соседа.
- OpenConfirm: Open сообщение получено от соседа и роутер ждет Keepalive или Notification message. Если от соседа не приходит keepalive до истечения hold timer, то роутер генерирует Notification message, с инфо, что hold timer expired и переведет сессию в Idle. Если keepalive получен, то соседство переходит в Established state.
- Established: BGP сессия установлена, пиры начинают обмениваться информацией, используя: Update, Keepalive, Notification сообщений.
Hold timer может быть разным у пиров. При установлении сессии будет выбран наименьший.
Tips
Если сессия установилась в Established, но через какое-то время перешла в Idle по Hold timer expared (скорее всего через 90sec = 3*keepalive), то первым делом проверьте MTU на канале между роутерами.
Если MTU где-то по пути зарезан/не соответствует MTU на интерфейсах bgp-пиров, можно либо решить вопрос с MTU на найденном проблемном участке, либо можно установить для сессии вручную размер mss (maximum segment size):
set protocols bgp group clients neighbor 1.1.1.1 tcp-mss 1470
Признаки подобной проблемы в логах:
Jan 1 00:18:18.553797 bgp_io_mgmt_cb:1777: NOTIFICATION sent to 1.1.1.1 (Internal AS 64777): code 4 (Hold Timer Expired Error), Reason: holdtime expired for 1.1.1.1 (Internal AS 64777), socket buffer sndcc: 0 rcvcc: 0 TCP state: 4, snd_una: 733415251 snd_nxt: 733415251 snd_wnd: 16384 rcv_nxt: 4248562819 rcv_adv: 4248579203, hold timer 90s, hold timer remain 0s, last sent 6s, TCP port (local 52746, remote 179) Jan 1 00:18:18.553889 BGP SEND message type 3 (Notification) length 21 Jan 1 00:18:18.553901 BGP SEND Notification code 4 (Hold Timer Expired Error) subcode 0 (unused) Jan 1 00:18:18.554014 bgp_peer_close_and_restart: closing peer 1.1.1.1 (Internal AS 64777), state is 7 (Established) event HoldTime Jan 1 00:18:18.554064 RPD_BGP_NEIGHBOR_STATE_CHANGED: BGP peer 1.1.1.1 (Internal AS 64777) changed state from Established to Idle (event HoldTime) (instance master)
Сообщения
Все сообщения имеют Header
0 1 2 3 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 2 3 4 5 6 7 8 9 0 1 +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | | + + | | + + | Marker | + + | | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+ | Length | Type | +-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+-+
BGP header содержит:
- marker - 16 октетов, установлены в "1". Обозначает, что это bgp-пакет
- lenght - размер пакета (16bit)
- type - тип сообщения
- 1 - OPEN
- 2 - UPDATE
- 3 - NOTIFICATION
- 4 - KEEPALIVE
- 5 - ROUTE-REFRESH [определен в RFC 2918]
Типы пакетов:
- Open (type 1) - отправляется только на стадии установления соседства. Содержит параметры BGP соседа: AS, auth-type (+ ключ, если есть аутентификация).
- Update (type 2) - передает info о добавлении или удалении маршрутов между соседями. Update содержит в себе Path, его атрибуты и вложенные префиксы, у которых эти атрибуты одинаковые. Не отправляются по таймеру, приходят, только когда изменился сам префикс, его атрибуты или BGP-сессия. В зависимости от policy, на локальном роутере, часть routing info может быть отброшена и помещена в hidden.
- Notification (type 3) - в случае если что-то пошло не так: не прошел keepalive или update, пришла не поддерживаемая опция, ... Существуют стандартизированные коды ошибок (operation code | opcode). Пакет состоит из header + opcode+subcode + data (описание ошибки - для диагностики).
- Keepalive (type 4)- для удостоверения, что с соседством все ok. Отправляется каждые 30 sec. По дефолту hold-timer = 3 * keepalive = 90sec - время, после которого соседи рушат соседство (если в это время не пролетело ни одного keepalive). Можно выставить holdtimer = 0. Если у одного соседа = 0, у другого нет, то будет согласовано ненулевое значение holdtimer для сессии.
keepalive message = BGP header без payload
- Refresh - soft clearing BGP сессии.
BGP Operations
BGP хранит маршруты в трех местах:
- Adjacency-RIB-IN: все полученные маршруты от пиров
- RIB-Local: маршруты локального роутера, используемые для передачи трафика. Тут хранятся только активные маршруты.
- Adjacency-RIB-OUT: маршруты, которые будут отправляться пирам. Передаваться могут только активные маршруты. (advertise-inactive исправляет данную ситуацию).
Передача маршрутов производится по правилам (чтобы избежать routing loops):
- IBGP пиры передают маршруты, полученные от EBGP другим IBGP пирам.
- EBGP пиры передают маршруты, полученные от EBGP и IBGP другим EBGP пирам
- IBGP пиры не передают маршруты, полученные от других IBGP пиров. Поэтому для того, чтобы получить всю маршрутную информацию, требуется full-mesh связность. Либо использование RR.
По умолчанию IBGP пиры не меняют next-hop для маршрутов, полученных от EBGP.
Решается:
- настройкой next-hop self в рамках export policy к remote PE/RR.
- добавить p2p интерфейс с EBGP пиром в IGP как passive.
- анонс p2p сети по IGP. Export policy для IGP протокола.
- настройки статического маршрута на каждом IBGP до удаленного EBGP пира.
- настроить IGP соседство с EBGP пиром.
Атрибуты (BGP attributes)
Включаются в Update сообщения и описывают BGP префиксы. Атрибуты используются для выбора активного пути.
Атрибуты, при выборе best, считаются лучшими с наименьшими значением Это правило касается всех атрибутов, кроме Local Preference
Атрибуты пути разделены на 4 категории:
- Well-known mandatory — все маршрутизаторы, работающие по протоколу BGP, должны распознавать эти атрибуты. Должны присутствовать во всех обновлениях (update).
- Well-known discretionary — все маршрутизаторы, работающие по протоколу BGP, должны распознавать эти атрибуты. Могут присутствовать в обновлениях (update), но их присутствие не обязательно.
- Optional transitive — могут не распознаваться всеми реализациями BGP. Если маршрутизатор не распознал атрибут, он помечает обновление как частичное (partial) и отправляет его дальше соседям, сохраняя не распознанный атрибут.
- Optional non-transitive — могут не распознаваться всеми реализациями BGP. Если маршрутизатор не распознал атрибут, то атрибут игнорируется и при передаче соседям отбрасывается.
Local preference
✔️Well-known Discretionary
- Указывает маршрутизаторам внутри автономной системы как выйти за её пределы.
- Больший приоритет выигрывает.
- Этот атрибут передается только в пределах одной автономной системы => работает только для IBGP.
- На маршрутизаторах Cisco и Juniper по умолчанию значение атрибута — 100.
- Если EBGP-сосед получает обновление с выставленным значением local preference, он игнорирует этот атрибут.
- В Junos lpf можно задать через policy и в protocol bgp. Если задан обоими способами, то будет назначен lpf из policy.
- Обычно используется на бордерах.
Когда в сети есть 2 бордера, которые получают один и тот же маршрут извне, и бордеры навешивают одинаковый повышенный lpf через export policy, в таком случае соседи IBGP получат маршрут с измененным lpf, но трафик не сможет по-правильному пути выйти из AS. Из-за того что бордеры тоже друг от друга будут получать маршрут с повышенным lpf. Решение: правильно менять lpf через import policy.
Autonomous system path
✔️Well-known Mandatory
- Описывает через какие автономные системы надо пройти, чтобы дойти до сети назначения.
- Номер AS добавляется при передаче обновления из одной AS eBGP-соседу в другой AS.
Используется для:
- обнаружения петель
- влияние на path selection с помощью prepending (делается через export policy)
set protocols bgp group int export longer-as-path set policy-options policy-statement longer-as-path term 1 then as-path-prepend "1111 1111 1111"
show route advertising-protocol bgp 10.200.86.2 inet.0: 32 destinations, 32 routes (32 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path * 172.17.0.0/24 Self 100 1111 1111 1111 [1111] I
Обозначение:
- [] - local AS
- {} - AS sets - группы AS, порядок не имеет значение. Возникает при агрегировании маршрутов.
- () - confederation
- ([]) - confederation sets
Каждый сегмент атрибута AS path представлен в виде поля TLV (path segment type, path segment length, path segment value):
- path segment type — поле размером 1 байт для которого определены такие значения:
- 1 — AS_SET: неупорядоченное множество автономных систем, через которые прошел маршрут в сообщении Update,
- 2 — AS_SEQUENCE: упорядоченное множество автономных систем, через которые прошел маршрут в сообщении Update
- path segment length — поле размером 1 байт. Указывает сколько автономных систем указано в поле path segment value
- path segment value — номера автономных систем, каждая представлена полем размером 2 байта.
Операторы регулярных выражений
| {m,n} | От m до n |
| {m} | m |
| {m,} | m или более |
| * | Все |
| + | 1 или более |
| ? | 0 или 1 |
| | | Один из двух |
| ^ | Начало community |
| $ | Конец community |
| [] | Список или массив букв или цифр |
| ( ) | Группирует символы |
| () | Ничего (null) |
. - любой знак (одна точка - один любой знак, 3 точки - три любых символа).
Next-hop
✔️Well-known Mandatory
- Это IP-адрес eBGP-маршрутизатора, через который идет путь к сети назначения.
- Атрибут меняется при передаче префикса в другую AS (по-умолчанию подставляется ip-адрес bgp-соседа)
- Атрибут не меняется при передаче префикса в ту же AS
Next-hop resolution
- Next-hop self
- Export direct into IGP: проанонсировать p2p сеть с EBGP peer, который прислал префикс.
- IGP passive interface: интерфейс в сторону EBGP соседа.
- Static routes: тут возникает проблема с тем, что придется на всех IBGP роутерах прописывать этот маршрут. Лучше выбрать другой способ.
- IGP adjacency on inter-AS links to EBGP peers: тоже плохой вариант. Опсано и зачем тогде вообще разные AS. Лучше выбрать другой способ.
Можно изменить с помощью policy на выходе (export к IBGP):
set policy-options policy-statement nexthop-self term localpref then next-hop self
Или же на входе (import от EBGP peer):
set policy-options policy-statement nexthop-peer term localpref then next-hop peer-address
Origin
✔️Well-known Mandatory
Атрибут Origin — указывает на то, каким образом был получен маршрут в обновлении. Меняется с помощью policy.
| 0 | IGP | NLRI получена внутри исходной автономной системы |
| 1 | EGP | NLRI выучена по протоколу Exterior Gateway Protocol (EGP) - протокол уже давно не используется. |
| 2 | Incomplete | NLRI была выучена каким-то другим образом, скорей всего через redistribution. |
Atomic aggregate
✔️Well-known Discretionary
Aggregator
✔️Optional Transitive
Communities
✔️Optional Transitive
- Тегирование маршрутов
- Существуют предопределенные значения (well-known), которые не требуется определять локально на своем оборудовании
- По умолчанию не пересылаются соседям
- Одному маршруту может быть присвоено несколько communities
- Community могут быть критерием в policy для изменения других атрибутов BGP, например lpf.
- Один из вариантов применения: передается соседней AS для управления входящим трафиком
Значения от 0x00000000 до 0x0000FFFF и от 0xFFFF0000 до 0xFFFFFFFF зарезервированы.
Как правило community отображаются в формате ASN:VALUE. В таком формате, доступны для использования community от 1:0 до 65534:65535. В первой части указывается номер автономной системы, а во второй значение community, которое определяет политику маршрутизации трафика.
Некоторые значения communities предопределены. RFC1997 определяет три значения таких community. Эти значения должны одинаково распознаваться и обрабатываться всеми реализациями BGP, которые распознают атрибут community.
Если маршрутизатор получает маршрут, в котором указано предопределенное значение communities, то он выполняет специфическое, предопределенное действие основанное на значении атрибута.
Предопределенные значения communities (Well-known Communities):
no-export (0xFFFFFF01)
Все маршруты которые передаются с таким значением атрибута community не должны анонсироваться за пределы AS. То есть, маршруты не анонсируются EBGP-соседям, но анонсируются внешним соседям в конфедерации.
Пример использования
AS1 подключена к AS2 двумя линками (multinoming). AS1 анонсирует 172.17.0/16 в AS2. Для оптимальной маршрутизации, AS1 хочет посылать некоторые более специфичные маршруты через один из этих линков, при этом остальному интернету вовсе не обязательно получать эти специфики. Для этой цели AS1 использует community no-export, и посылает 172.17.0/17 в один из стыков с AS2, и 172.17.128/17 во второй стык. AS2 видит эти маршруты и выбирает их как более специфичные. Кроме того, эти маршруты видят все iBGP-соседи в пределах AS2. Тем не менее, за пределы AS2 в Интернет анонсируется только 172.17.0/16.
AS customer имеет 2 ISP (AS1, AS2). AS1 - основной. Если AS customer хочет получать выход в инет только через AS1, то в сторону AS2 можно просто посылать маршруты с no-export. Но при этом важно, что при падении AS1, AS customer будет доступна только локальным пользователям AS2, но не всему интернету.
no-advertise (0xFFFFFF02)
Все маршруты которые передаются с таким значением атрибута community не должны анонсироваться другим BGP-соседям.
no-export-subconfed (0xFFFFFF03)
Все маршруты которые передаются с таким значением атрибута community не должны анонсироваться внешним BGP-соседям (ни внешним для конфедерации, ни настоящим внешним соседям). В Cisco это значение встречается и под названием local-as.
Маршрутизаторы, которые не поддерживают атрибут community, будут передавать его далее, так как это transitive атрибут.
set policy-options policy-statement community test-community members [65510:555 65610:999] - [x and y] set policy-options policy-statement test term 1 then community (add|set|delete) test-community
set policy-options policy-statement community all-community members "*:*"
С communities широко используются регулярные выражения.
Примеры
100:* - all posible community values with AS 100.
11.1:666 - 1101:666, 1111:666, 1121:666, etc.
show route community *:20 show route community-name community-test detail
Список операторов регулярных выражений для Community
| {m,n} | От m до n |
| {m} | m |
| {m,} | m или более |
| * | Все |
| + | 1 или более |
| ? | 0 или 1 |
| | | Один из двух |
| ^ | Начало community |
| $ | Конец community |
| [] | Список или массив букв или цифр |
| ( ) | Группирует символы |
| () | Ничего (null) |
Действия с community
- add - добавляет к текущим community префикса указанное community
- delete - удаляет только указанное community
- set - заменяет существующие community на указанное
Multi exit discriminator (MED)
✔️Optional Non-transitive
- Используется для информирования eBGP-соседей о том, какой путь в автономную систему более предпочтительный.
- Атрибут передается между автономными системами, но в Junos передается только EBGP пиру и не распространяется дальше по AS.
- Маршрутизаторы внутри соседней автономной системы используют этот атрибут, но, как только обновление выходит за пределы AS, атрибут MED отбрасывается.
- Чем меньше значение атрибута, тем более предпочтительна точка входа в автономную систему.
- Исходя из названия - используется только в тех случаях, когда между AS есть несколько линков.
- Можно использовать для балансировки.
Сравнение MED (при прочих равных) происходит если один и тот же префикс приходит от одной AS.
Если будет анонс этого префикса с более низким MED, но из другой AS, то он не будет рассматриваться как вероятный вариант для использования.
Это дефолтное поведение, которое можно изменить с помощью:
- always-compare-med: при этом не будет иметь значение разные AS или одна, просто активным станет маршрут с самым низким MED.
- cisco-non-determenistic: выбор основан на том, когда маршрут пришел. Juniper не рекомендует использовать.
MED назначается с помощью policy.
Возможные операции с MED
Внутри policy metric - это обозначение MED атрибута.
Можно использовать как в from, так и в then. Then: назначение метки - metric 50, добавить к существующей метки - metric add 50, вычесть из metric subtract 50.
MED можно назначить внутри protocols bgp:
[edit protocols bgp group AS-100] type external local-as 200 neighbor 1.1.1.1 metric-out 50 <= определенное значение neighbor 2.2.2.2 metric-out igp <= текущая IGP метрика neighbor 3.3.3.3 metric-out minimum-igp <= минимальная IGP мтерика, когда-либо изученная neighbor 4.4.4.4 metric-out igp 5 <= добавить или вычесть из IGP метрики
MED также можно назначить аналогичным образом через policy:
[edit policy-optinos policy-sttement new-metric]
term IGP
then metric igp offset
term minimum-igp
then metric minimum-igp offset
При использовании metric igp на префикс вешается MED, равный IGP метрики до роутера, который прислал этот префикс. При изменениях IGP metric, будет меняться и MED.
При использовании metric minimum-igp MED не будет меняться при изменениях IGP метрики.
При агрегировании маршрутов - MED становится = 0.
Если между роутерами передаются агрегированный маршрут и вложенный в него в MED, то вложенный будет передан с MED, а агрегированный - с MED = 0.
Это дефолтное поведение и альтернатив этому нет.
Weight (проприетарный атрибут Cisco)
Атрибут Weight:
- Позволяет назначить "вес" различным путям локально на маршрутизаторе.
- Используется в тех случаях, когда у одного маршрутизатора есть несколько выходов из автономной системы (сам маршрутизатор является точкой выхода).
- Имеет значение только локально, в пределах маршрутизатора.
- Не передается в обновлениях.
- Чем больше значение атрибута, тем более предпочтителен путь выхода.
Механизмы управления трафиком
Входящим
- AS path prepend
- Community (если поддерживает провайдер)
- MED (подключение к одной и той же AS)
- Анонс разных префиксов через разных ISP
Исходящим
- Проприетарный атрибут Cisco weight (локально на маршрутизаторе)
- Local Preference (локально в AS)
- Косвенно можно политикой навешивать med на префиксы от пира и в зависимости от этого будет также регулироваться исходящий трафик.
Выбор лучшего пути (BGP Active Route Selection)
- Проверяем, что резолвится next-hop (без это маршрут и активным то не будет :/ )
- Route Preference (Admin distance)
- БОльший local preference (Inactive reason: Local Preference)
- Кратчайший AS-path (Inactive reason: AS path)
- Меньший Origin value (Inactive reason: Origin)
- Меньший MED value (Inactive reason: Route Metric or MED comparison)
- EBGP peer предпочтительней IBGP peer (Inactive reason: Interior > Exterior > Exterior via Interior)
- C кратчайшей IGP метрикой к Protocol next-hop (Inactive reason: Not Best in its group – IGP metric)
- Если префикс получен по IBGP, то используем префикс от пира с наименьшим RID (Inactive reason: Not Best in its group – Router ID)
- Если префикс получен по EBGP, то используем более старый активный префикс (считается более стабильным) (Inactive reason: Not Best in its group – Active preferred)
- При использовании RR: кратчайший cluster list length (Inactive reason: Not Best in its group – Cluster list length)
- Наименьший router-ID (Inactive reason: Not Best in its group – Router ID)
- Наименьший Source IP address (Inactive reason: Not Best in its group - Update source)
В Juniper можно посмотреть причину неактивности маршрута: Inactive reason в выводе sh route protocol bgp x.x.x.x extensive
Дефолтное поведение для EBGP маршрутов может быть изменено: path-selection external-router-id. При включении этой функции для роутера выбор активного EBGP маршрута от разных роутеров будет делаться по наименьшему router-id.
- Route Preference (Admin distance) - не передается по ibgp, ebgp. Может только навешиваться через import-policy или в настройках bgp на любом уровне иерархии.
Multipath
Один и тот же маршрут прилетает с двух пиров одной AS или несколько копий маршрута прилетает с одного пира. Активный маршрут будет вставлен в routing table с несколькими next-hop и трафик будет балансироваться между двумя пирами (в forwarding table все же будет вставляться один next-hop). Для inactive маршрутов будет указан один next-hop. Multipath не вставит маршруты с одинаковым MED-plus-IGP cost, при разных IGP метриках до пиров. На роутере глобально должен быть включен load-balancing.
При включенном multipath, алгоритм выбора лучшего пути игнорирует router ID и peer ID.
До включения:
mortlach> show route protocol bgp terse inet.0: 30 destinations, 34 routes (30 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both A Destination P Prf Metric 1 Metric 2 Next hop AS path * 172.17.0.0/24 B 170 100 >192.168.86.21 I B 170 100 >192.168.86.42 I * 172.17.1.0/24 B 170 100 >192.168.86.21 I B 170 100 >192.168.86.42 I * 172.17.2.0/24 B 170 100 >192.168.86.21 I B 170 100 >192.168.86.42 I * 172.17.3.0/24 B 170 100 >192.168.86.21 I B 170 100 >192.168.86.42 I mortlach> show route forwarding-table destination 172.17.0.0/24 Routing table: default.inet Internet: Destination Type RtRef Next hop Type Index NhRef Netif 172.17.0.0/24 user 0 indr 262142 5 192.168.86.21 ucst 547 5 ge-0/0/0.90 - выбран активным, из-за меньшего router-ID (10.200.86.4 vs 10.200.86.8)
После:
mortlach> show route protocol bgp terse inet.0: 30 destinations, 34 routes (30 active, 0 holddown, 0 hidden) + = Active Route, - = Last Active, * = Both A Destination P Prf Metric 1 Metric 2 Next hop AS path * 172.17.0.0/24 B 170 100 192.168.86.21 I >192.168.86.42 B 170 100 >192.168.86.42 I * 172.17.1.0/24 B 170 100 192.168.86.21 I >192.168.86.42 B 170 100 >192.168.86.42 I * 172.17.2.0/24 B 170 100 192.168.86.21 I >192.168.86.42 B 170 100 >192.168.86.42 I * 172.17.3.0/24 B 170 100 192.168.86.21 I >192.168.86.42 B 170 100 >192.168.86.42 I mortlach> show route forwarding-table destination 172.17.0.0/24 Routing table: default.inet Internet: Destination Type RtRef Next hop Type Index NhRef Netif 172.17.0.0/24 user 0 indr 262143 5 192.168.86.42 ucst 588 7 ge-0/0/0.50 - изменился, т.к. router ID уже не влияет на выбор лучшего пути
Link Bandwidth Extended Community
При включенном multipath можно задать желаемую балансировку между линками через extended community. Это механизм описан в draft-ietf-idr-link-bandwidth-06, и не является стандартизированным, следовательно, возможно, он не будет работать с некоторыми вендорами. В JunOS поддерживается.
Позволяет делать балансировку пропорционально заданным в community скоростям.
Пример использования:
R1 и R2 соединены напрямую через два сабинтерфейса, на каждом из которых висит своя /30 сеть
| | ge-0/0/0.10 ----- ge-0/0/0.10 | | | R1 | | R2 | | | ge-0/0/0.20 ----- ge-0/0/0.20 | |
Конфиг R1:
R1> show configuration protocols bgp
group ebgp {
multipath;
neighbor 10.1.0.2 {
description R2;
export from-direct;
peer-as 2222;}
neighbor 10.2.0.2 {
description R2;
export from-direct;
peer-as 2222;}}
Конфиг R2:
set interfaces lo0 unit 0 family inet address 2.2.2.2/32 set policy-options policy-statement bw20 then community add bw20 set policy-options policy-statement bw80 then community add bw80
set policy-options policy-statement from-direct term redistribute-direct from protocol direct set policy-options policy-statement from-direct term redistribute-direct then accept set policy-options policy-statement from-direct term default then reject
set policy-options community bw20 members bandwidth:2222:2500000; // 2500000 байт в секунду — это 20% от 100Мегабит
set policy-options community bw80 members bandwidth:2222:10000000; // 10000000 байт в секунду — это 80% от 100Мегабит
R2> show configuration protocols bgp
group ebgp {
neighbor 10.1.0.1 {
description R1;
export [ bw20 from-direct ]; // На одно из соседств навешивается community bw20
peer-as 1111;}
neighbor 10.2.0.1 {
description R1;
export [ bw80 from-direct ]; // На второе соседство навешивается community bw80
peer-as 1111;}}
Что получилось:
R1> show route 2.2.2.2 extensive
inet.0: 11 destinations, 19 routes (11 active, 0 holddown, 0 hidden)
2.2.2.2/32 (2 entries, 1 announced)
TSI:
KRT in-kernel 2.2.2.2/32 -> {10.2.0.2, 10.1.0.2}
*BGP Preference: 170/-101
Next hop type: Router, Next hop index: 262145
Address: 0x9404010
Next-hop reference count: 8
Source: 10.1.0.2
Next hop: 10.2.0.2 via ge-0/0/0.20 balance 80%
Next hop: 10.1.0.2 via ge-0/0/0.10 balance 20%, selected
State: <Active Ext>
Local AS: 1111 Peer AS: 2222
Age: 1:20:49
Task: BGP_2222.10.1.0.2+179
Announcement bits (1): 0-KRT
AS path: 2222 I
Communities: bandwidth:2222:2500000
Accepted Multipath
Localpref: 100
Router ID: 2.2.2.2
Multihop
Возможность поднять EBGP peering между роутерами, не имеющих прямого физического соединения. Сессия устанавливается на lo интерфейсах.
Важно в конфиге задать multihop. В таблице маршрутизации должен быть маршрут до пира.
При поднятии сессии на Lo интерфейсах используем:
- set system default-address-selection - будет браться адрес lo автоматически
- local-address (bgp, group или neighbor) - более специфичен, поэтому если надо будет - перебьет уже настроенный default-address-selection
TTL = 1 задаем, чтобы соседство установилось точно с одним ближайшим роутером. (либо другое значение, если роутер далеко)
blair> show route 10.200.86.4 10.200.86.4/32 *[IS-IS/18] 00:00:03, metric 10 to 192.168.86.49 via ge-0/0/0.80 > to 192.168.86.17 via ge-0/0/0.100
Config
set protocols bgp group int type internal set protocols bgp group int multihop ttl 1 set protocols bgp group int local-address 10.200.86.1 set protocols bgp group int neighbor 10.200.86.4
Т.к. между роутерами теперь 2 физических линка, то можно балансировать трафик между ними.
Modifying AS Path
Option 1: remove-private
Диапазон: 64512 - 65534
Роутер, на котором настроен remove-private перед передачей префиксов удаляет из AS path AS из указанного выше диапазона.
Можно настраивать на всех уровнях: protocols bgp, group, neighbor.
Option 2: local-as
set routing-options autonomous-system 1111 set protocols bgp group ebgp neighbor 10.1.0.2 peer-as 2222 set protocols bgp group ebgp neighbor 10.1.0.2 local-as 3333
При такой конфигурации R1, EBGP-сосед, который ожидает, что у R1 будет AS3333 сможет установить соседство с R1, хотя, по факту R1 принадлежит AS1111. Результат:
R1> show bgp neighbor Peer: 10.1.0.2+179 AS 2222 Local: 10.1.0.1+62745 AS 3333 Type: External State: Established Flags: <Sync> Last State: OpenConfirm Last Event: RecvKeepAlive ... Holdtime: 90 Preference: 170 Localpref: 110 Local AS: 3333 Local System AS: 1111 Number of flaps: 0 Peer ID: 2.2.2.2 Local ID: 1.1.1.1 Active Holdtime: 90 ...
Зачем это нужно
Предположим, оператор с AS1111 купил сеть оператора с AS3333. У AS3333 были свои клиенты, подключенные по BGP, которые не готовы или не хотят изменять конфигурацию на своих роутерах. В таком случае можно временно применить опцию local-as, чтобы выступить для них от лица предыдущей AS (в примере - 3333), но внутри сети перевести инфораструктуру на AS1111.
Если добавить ключевое слово private:
set protocols bgp group ebgp neighbor 10.1.0.2 peer-as 2222 set protocols bgp group ebgp neighbor 10.1.0.2 local-as 3333 private
То R1 вообще не будет добавлять AS3333 при анонсе маршрутов, получаемых от 10.1.0.2 своим соседям.
as-override
CE1 (AS 65500) <> PE (AS 1111) <> P (AS 1111) <> PE (AS 1111) <> CE2 (AS 65500)
Если на сети ISP есть 2 сессии с пирами из одной AS, то при передаче маршрутов, полученных от одного site этой AS второму site'у, второй site не примет такой префикс, потому что в AS path будет дважды указана его AS - это routing loop.
65500 1111 I - роутер с AS 65500 не примет префикс с таким AS path.
set protocols bgp group int neighbor 10.200.86.4 as-override
Можно конфигурировать для группы или соседа.
Роутер ISP на полученном префиксе смотрит в AS path, AS пира заменяем на свою. При передаче префикса второму site ISP делает стандартный prepend своей AS. В итоге пиру в AS 65500 прилетит префикс с таким AS path:
1111 1111 I
loops
Еще один способ решения ситуации, описанной в примере выше - чтобы CE2 получил маршрут своего удаленного site:
На CE2:
set routing-options autonomous-system 65500 loops 2
Тогда на CE2 прилетит префикс с AS path:
1111 65500 I
и роутер это сожрет.
Опции настройки для пиров
- passive - локальный роутер перестает слать open message. Чтобы сессия поднялась, open message теперь должно прийти от удаленного пира.
blair# top show | compare set protocols bgp group int neighbor 10.200.86.4 passive
Feb 11 22:07:58.812668 BGP SEND message type 1 (Open) length 59 Feb 11 22:07:58.856999 BGP RECV message type 1 (Open) length 59
После задания passive для пира:
Feb 11 22:12:22.128876 BGP RECV message type 1 (Open) length 59
- allow - принимает open message только из указанной сети. Можно указать только для определенной группы:
set protocols bgp group int allow 10.200.86.0/24
- prefix-limit: ограничивает значение полученных префиксов от пира. Можно применять на разных уровнях иерархии.
set protocols bgp group int neighbor 10.200.86.4 family inet unicast prefix-limit maximum 1500 set protocols bgp group int neighbor 10.200.86.4 family inet unicast prefix-limit teardown 100 (%) idle-timeout 10 (min);}}}
- hold-time: меняем hold timer. По дефолту 90 sec. Можно применять на разных уровнях иерархии.
set protocols bgp hold-time 120
- advertise-peer-as: позволяет EBGP маршруты передавать обратно EBGP пиру. Но тогда и у пира должен быть настроен as loops, чтобы он не отбросил префикс с лупом в AS-Path.
set protocols bgp group int advertise-peer-as
Route Reflection
Описан в RFC 4456
Концепция
Заменяем full-mesh на сети между PE.
- Позволяет iBGP-спикеру анонсировать другим iBGP-маршрутизаторам маршруты, полученные через iBGP
- RR пересылает только активные маршруты клиентам (это iBGP соседи RR, которые не являются RR)
- RR по умолчанию не меняет IBGP атрибуты.
- Для предотвращения петель существуют два новых атрибута:
- Cluster List (1 или более cluster ID)
- Originator ID - ID роутера, который первым переслал маршрут в AS.
Распространение маршрутов при использовании RR

Будем использовать следующие обозначения:
- IBGP rr-client - IBGP сосед в кластере
- IBGP NON-rr-client - IBGP сосед не в кластере
- EBGP - EBGP сосед
Распространение маршрутов происходит следующим образом:
- IBGP rr-client > IBGP rr-client + IBGP NON-rr-client
- IBGP NON-rr-client > IGBP rr-client
- IBGP NON-rr-client <> IBGP NON-rr-client - не передается
- EGBP > IBGP rr-client + NON-rr-client
Если включить no-client-reflect, то это запретит анонсить префиксы между клиентами кластера. В таком случае, если требуется сохранить связность между этими клиентами - нужно настроить между ними full-mesh. Такой вариант развитий по идее может понадобиться только при иерархичном роут-рефлектинге (о нем ниже).
RR добавляет/изменяет атрибуты (без политик по дефолту):
- Originator ID
Router ID первого роутера, который заслал маршрут в AS.
- Cluster List (Cluster ID)
Список, включающий ID всех RR, которые обрабатывали данный префикс. Если RR получит маршрут, у которого в cluster list будет ID этого RR, то он его дропнет. Участвует при выборе активного маршрута (активным становится с наименьшим cluster list). Cluster ID добавляется к cluster list, когда маршрут отправляется. Cluster ID должен быть уникальным в рамках AS. При использовании нескольких RR, можно для всех использовать одинаковый cluster ID.
+ такой схемы: в таблице будет меньше маршрутов и при такой схеме можно добиться хорошей отказоустойчивости в сети.
Правила работы с Originator и Cluster List:
- для EBGP или любого другого протокола, отличного от IBGP, originator и сluster list не добавляются
- для IBGP client<>client / client<>non-client:
- originator добавится только если до этого его не существовало.
- Cluster list дополнится новым cluster ID.
- Cluster ID будет установлен, если его не было ранее.
2 RR в кластере
Соседство между RR можно устанавливать как внутри отдельной группы для кластера, так и в отдельной группе. В обоих случаях при передаче маршрутов между RR петель не будет, т.к. cluster ID будет одинаковыми. Каждый из RR в кластере устанавливает IBGP с другими RR, не входящих в кластер. В подобных схемах все-таки тоже стараются использовать уникальные cluster ID.
Configuration
Если на сети несколько RR, то соседство между ними может быть как в отдельной группе от RR-clients (IBGP), так и в той же группе что и клиенты. Между RR - full-mesh.
set protocols bgp group RR type internal set protocols bgp group RR peer-as 65513 set protocols bgp group RR neighbor 2.2.2.2 set protocols bgp group RR neighbor 3.3.3.3
RR-clients конфигурируются в отдельной группе, где должен быть включен: "cluster x.x.x.x"
set protocols bgp group RR-clients cluster 1.1.1.1
Со стороны клиентов конфигурация стандартная для IBGP - простое соседство с RR на lo0 адресах (с включенным multihop!!)
Hierarchical Route Reflection

Отличие от предыдущих: в схеме появляются не только RR и client, но еще и роутеры, выполняющие обе функции в рамках разных кластеров. Clients могут устанавливать IBPG между собой full-mesh. Это удобно использовать, чтобы clients могли использовать маршруты от других clients нативно, без обработки RR. Чтобы RR не флудил копиями маршрутов, на нем можно включить no-client-reflect, это отключит пересылку маршрутов, полученных внутри кластера. Внешние маршруты при этом продолжают пересылаться.
Modifying Attributes on the RR
Все атрибуты BGP изменяются через policy. Если на RR есть EBGP, то с большой вероятностью будет активна ф-ия: next-hop-self. При этом, у маршрутов, полученных от client, также next-hop будет меняться. Что приведет к не оптимальному форвардингу трафика (должен идти напрямую к original роутеру, а будет идти через RR). Чтобы менять next-hop только у external: в policy матчим по interface ли neighbor.
set policy-option policy-statement nhs term EBGP from protocol bgp set policy-option policy-statement nhs term EBGP from neighbor 2.2.2.2 set policy-option policy-statement nhs term EBGP the next-hop self
Fake-group
Данная проблема описана в KB20870 (https://kb.juniper.net/InfoCenter/index?page=content&id=KB20870).
Более подробное описание и рекомендации по предотвращению https://www.juniper.net/documentation/en_US/junos/topics/example/bgp-vpn-session-flap-prevention.html
По факту функционал RR включается/выключается только при добавлении/удалении соседу в группе с клиентами (с cluster).
Если на маршрутизаторе настроены EBGP с клиентами или IBGP c RR, для которых в конфигурации группы включены vpn-address-family, (inet-vpn, inet6 inet-mpvn, inet-mdt, inet6-mpvn, l2vpn, iso-vpn) и на маршрутизаторе в этих группах производится добавления первого соседа или удаления последнего, Juniper рестартует BGP сессии с RR и c EBGP пирами в VPN-address-family для отсылки NLRI с новой (удалением старой) address-family.
Для предотвращения подобных ситуаций можно предпринять следующие шаги:
- на каждом RR создана fake группа (для исключения проблемы удаления последнего соседа в группе).
- на каждом PE создана fake группа (для исключения проблемы включения нового клиента с EBGP + vpn-family)
Configuration
Fake группа имеет следующий вид для RR и PE:
group fake-vpn {
type external;
description "-- Preventing mpbgp sessions flap --";
passive;
family inet {
any;
family inet-vpn {
any;
family iso-vpn {
unicast;
family l2vpn {
signaling;
family evpn {
signaling;
family inet-mvpn {
signaling;
family inet-mdt {
signaling;
neighbor 101.101.101.101 {
peer-as 101;
IPv6 (6PE)
Если у нас есть настроенная ipv4 сеть и мы захотели передавать трафик и для ipv6 адресов (используя MPLS), то:
- требуется настроить family inet6 labeled-unicast explicit-null на сессии pe<>rr
set protocols bgp group ibgp-rr family inet6 labeled-unicast explicit-null
эта family навешивает на ipv6 префикс label 2 (explicit-null для ipv6), что позволяет на сети в качестве транспорта использовать mpls, а на последнем роутере делать lookup в таблице inet6.0.
- на сети у нас скорей всего уже будет включен mapping ipv4 адресов в ipv6:
set system allow-v4mapped-packets
- при передаче префиксов pe->rr должен быть настроен в политике hext-hop self. При этом для ipv6 префиксов будет подставляться mapped ipv6 адрес lo0.
rr> show route receive-protocol bgp 172.30.5.5 inet.0: 56 destinations, 58 routes (55 active, 0 holddown, 1 hidden) Prefix Nexthop MED Lclpref AS path * 192.168.31.0/24 172.30.5.5 100 64514 I * 192.168.32.0/24 172.30.5.5 200 64514 I inet6.0: 7 destinations, 8 routes (7 active, 0 holddown, 0 hidden) Prefix Nexthop MED Lclpref AS path fd17:f0f4:f691:5::31/128 * ::ffff:172.30.5.5 100 64514 I
- на rr адреса ::ffff:172.30.5.5 не будет, поэтому полученный префикс будет в hidden, из-за неотрезовленного next-hop. Чтобы решить эту проблему прописываем статику:
rr> show configuration routing-options rib inet6.0 static route ::ffff:172.30.5.0/124 receive;
receive в данном случае позволяет сделать маршрут активным, не прибегая к форвардингу трафика.
- после этого рефлектор спокойно рефлектит маршрут своим клиентам.
- далее, pe получит префикс, но с принятым next-hop ::ffff:172.30.5.5 это префикс опять же не станет активным в таблице. Тут решение static с next-hop receive - не проканает, ибо нам нужно передавать трафик к префиксу, а не просто вставить его в таблицу маршрутизации. Тут прибегнем к варианту, который маршруты ldp для desct-ipv4 замапит в dest-ipv6 из inet.3 и поместит их в inet6.3 (для резолва ipv6 префиксов):
set protocols mpls ipv6-tunneling
rigel-r7> show route protocol ldp 172.30.5.5
inet.3: 25 destinations, 32 routes (8 active, 0 holddown, 22 hidden)
172.30.5.5/32 *[LDP/9] 01:17:08, metric 20
to 172.30.0.41 via ge-0/0/0.240, Push 319216
> to 172.30.0.46 via ge-0/0/3.244, Push 340912
rigel-r7> show route protocol ldp ::ffff:172.30.5.5
inet6.3: 8 destinations, 10 routes (8 active, 0 holddown, 0 hidden)
::ffff:172.30.5.5/128 *[LDP/9] 01:17:20, metric 20
to 172.30.0.41 via ge-0/0/0.240, Push 319216
> to 172.30.0.46 via ge-0/0/3.244, Push 340912
ну и проверяем, что и сам префикс стал активным:
rigel-r7> show route fd17:f0f4:f691:5::31/128
inet6.0: 20 destinations, 22 routes (20 active, 0 holddown, 0 hidden)
fd17:f0f4:f691:5::31/128 *[BGP/170] 00:50:51, localpref 100, from 172.30.5.41 AS path: 64514 I
to 172.30.0.41 via ge-0/0/0.240, Push 2, Push 319216(top)
> to 172.30.0.46 via ge-0/0/3.244, Push 2, Push 340912(top)
Кстати, ipv6 tunneling перетаскивает как ldp, так и rsvp маршруты в inet6.3.
Confederations
Описан в RFC 3065
Принципы
Цель: разбить global AS на sub-AS.
- sub-AS должна иметь уникальный номер (зачастую берут приватные AS).
- Внутри sub-AS между роутерами: full-mesh IBGP. Если внутри sub-AS будет слишком большая сеть, то в нее можно внедрить RR.
- Между sub-AS - EBGP = confederation BGP = CBGP. При прохождении маршрута через CBGP линк, роутер меняет AS path, включая туда AS sub-AS - этот метод - защита от петель. Другие атрибуты BGP не меняются.
Также в отличие от стандартного EBGP, в CBGP обычно соседство строится на loopback (добавляем multihop в настройки).
AS-path segment
- AS Confederation Sequence
При прохождение через CBGP линк, роутер добавляет sub-AS к AS-path в "()" в последовательности, как шел маршрут по сети.
AS Confederation Sequence не используется при выборе активного пути.
Этот атрибут имеет type code 3.
AS-path: (65000 65001 65002) 100 200
- AS Confederation Set
При агрегировании маршрутов внутри конфедерации, AS confederation sequence становится AS confederation set.
Этот атрибут имеет type code 4.
10.10.10.0/24 (65000 65001) 100
10.10.20.0/24 (65000 65002) 100
10.10.0.0/16 ({65000 65001 65002}) 100
Оба атрибута используются только для предотвращения петель внутри конфедерации.
При анонсировании маршрутов из конфедерации дальше по сети по EBGP, private AS (sub-AS) стираются, поэтому все конфедерации извне видны как одна большая глобальная AS. При этом не требуется отдельно включать (remove-private). В случае с конфедерациями, все приватные AS итак сотрутся.
Но все роутеры внутри конфедерации обязательно должны знать номер глобальной AS.
Configuration
Включение самой конфедерации на роутере - определяется в routing-options:
set routing-options autonomus-system 65000 set routing-options confederation 100 members [65000 65001 65002]
confederation <> - это номер public AS.
в качестве members - определяются все AS, включенные в конфедерацию.
R1
внутри конфедерации: set protocols bgp group sub-AS-65001 type internal set protocols bgp group sub-AS-65001 local-address 192.168.1.3 set protocols bgp group sub-AS-65001 neighbor 192.168.1.1 set protocols bgp group sub-AS-65001 neighbor 192.168.1.2 set protocols bgp group sub-AS-65001 neighbor 192.168.1.4
CBGP-link 1:
set protocols bgp group sub-AS-65000 type external set protocols bgp group sub-AS-65000 multihop set protocols bgp group sub-AS-65000 local-address 192.168.1.3 set protocols bgp group sub-AS-65000 peer-as 65000 set protocols bgp group sub-AS-65000 neighbor 192.168.0.3
CBGP-link 2:
set protocols bgp group sub-AS-65002 type external set protocols bgp group sub-AS-65002 multihop set protocols bgp group sub-AS-65002 local-address 192.168.1.3 set protocols bgp group sub-AS-65002 peer-as 65002 set protocols bgp group sub-AS-65002 neighbor 192.168.2.4
Route damping (flapping)
При различных обстоятельствах на сети могут возникать флапы маршрутов, что приводит к загрузке CPU на роутерах.
Чтобы избежать подобного поведения есть некоторые механизмы защиты от флапов, например: BGP route flap damping.
Damping игнорируется IBGP и работает только с EBGP и CBGP (confederation BGP).
Damping уменьшает кол-во update message, путем обозначения флапающих маршрутов непригодными стать активными маршрутами.
Принцип работы:
Когда маршрут прилетает на наш роутер (на котором настроен route damping), на префикс назначается значение merit = 0.
Как только роутер распознает некую нестабильность маршрута (префикс просто перестает долетать до роутера (или линк упал)):
- назначается merit = 1000, включается счетчик decay half-life. Если на роутер снова прилетит префикс, до того, как истечет таймер, то значение merit увеличится еще на 1000 +1000. И подобное поведение будет повторяться до превышения значения merit до supress (3000) - префикс в таком случае будет признан непригодным для использования.
После того, как префикс пропал и заново прилетел на роутер по BGP, его значение merit = 2000 (при дефолтных настройках)
Merit (last update/now): 1969/1938
Default damping parameters used
Last update: 00:00:27 First update: 00:00:49
Flaps: 2
После этого при исчезновении маршрута с роутера, его не будет видно в inet.0, но инфо можно будет посмотреть в
blair> show route damping history detail
После того, как будет превышен supress threshold, инфо о маршруте можно будет посмотреть:
blair> show route damping suppressed detail
Либо в hidden, если маршрут приходит от пира.
- если префикс передается от роутера, то он передается со значением merit = 1000.
- если изменяется path attribute, то префиксу ставится значение 500.
- decay half-life - кол-во минут после которого значение merit уменьшается вдвое, при поведении маршрута более стабильно. default = 15 min.
- max-supress - максимальное кол-во минут, которое маршрут проводит в состоянии hold-down. default = 60 min.
- reuse threshold - произвольное значение, после которого маршрут снова можно использовать. default = 750.
- supress threshold- произвольное значение, после которого маршрут больше нельзя использовать. default = 3000.
Config
Как только включаем на роутере damping, без заданных параметров, для работы будут использоваться дефолтные значения.
Параметры задаются через policy. Disable - для определенных префиксов удаляет merit, и убирает префикс из damping процесса (могут быть например public DNS).
set policy-options damping c11 half-life 30 set policy-options damping c11 reuse 1000 set policy-options damping c11 max-suppress 500
set policy-options policy-statement c11-damping then damping c11
set protocols bgp group c11 type external set protocols bgp group c11 damping set protocols bgp group c11 import c11-damping
Blackhole
Когда на сети определено специальное community для blackhole, и клиент посылает префикс, помеченный этим community, нужно реализовать блокировку трафика на нашей сети к этом префиксу. И желательно разослать этот префикс другим пирам и апстримам с их blackhole-community.
Блокировку трафика можно организовать несколькими способами.
1. зарулить трафик на префикс, у которого next-hop = discard.
set policy-options policy-statement blackhole from protocol bgp set policy-options policy-statement blackhole from community blackhole set policy-options policy-statement blackhole then next-hop 192.168.0.101 set policy-options policy-statement blackhole then accept set routing-options static route 192.168.0.101/32 discard set routing-options static route 192.168.0.102/32 discard
здесь без accept - видимо не происходит еще один lookup и next-hop остается unusable. Либо resolve происходит, но с next-hop discard маршрут не считается активным и остается в hidden.
Тема discard не раскрыта :)
2. зарулить на discard interface (dsc). - подробно лучше смотреть в документации Juniper.
3. сделать у префикса сразу next-hop discard.
set policy-options policy-statement blackhole from protocol bgp set policy-options policy-statement blackhole from community blackhole set policy-options policy-statement blackhole then next-hop discard set policy-options policy-statement blackhole then accept set policy-options community blackhole members "6451[0-9]:666"
без accept маршрут будет в hidden и не передастся своим ibgp соседям. (в hidden, так как next-hop unusable)
Политику применяем на клиентов и на ibgp сессии в рамках нашей aAS (+cbgp, если используем конфедерации)
Чтобы разослать префикс другим ebgp пирам добавляем еще одну строчку в политику:
set policy-options policy-statement blackhole then community add upstream-blackhole
TIPS:
- если в политике делать только then discard - это заблочит распространение префикса на сети, что не совсем решает проблему. Через нашу сеть все-равно будет идти трафик до этого dest, просто обходными путями.
- обычно клиенты шлют /32 префиксы с blackhole-community, а на import фильтрах у уважающих себя операторов есть ограничение по длине префикса (<24).
Поэтому, чтобы получить /32, добавляем в политику условие:
set policy-options policy-statement blackhole from route-filter 0.0.0.0/0 prefix-length-range /32-/32
BFD
Как известно, этот механизм используется в качестве обмена hello сообщениями с заданным интервалом, ниже, чем дефолтный интервал в других протоколах. Что позволяет протоколу быстрее обнаружить падение сессии.
Сильно нагружает CPU RE, поэтому с ним сильно перебарщивать не стоит.
Хосты устанавливают сессию и обмениваются hello.
Если перестали приходить hello, то BFD дает знать протоколу, что пропала связность между хостами.
- minimum-interval - минимальный интервал получения и отправления "hello" BFD. То есть это интервал с которым локальный роутер отправляет hello и интервал, с которым локальный роутер ждет ответа на свой hello. Также в конфиге можно отдельно задать transmit и receive minimum interval.
- multiplier - значение кол-ва пропущенных hello.
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection minimum-interval 500 [transmit+receive] set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection multiplier 4
или
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection minimum-receive-interval 500 [receive] set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection transmit-interval minimum-interval 500 [transmit]
BFD + graceful restart - не рекомендуется.
BFD + Routing Engine switchover event - не рекомендуется ниже 5000мс.
BFD + NSR - не рекомендуется ниже 2500мс.
для очень больших сетей с большим кол-вом bfd сессий - не ниже 300мс
Если значения таймеров у пиров не совпадают, то BFD использует наибольшее значение (используется режим adaptive-mode).
Это поведение по умолчанию можно выключить: no-adaptation.
set protocols bgp group upstream neighbor 1.1.1.1 bfd-liveness-detection no-adaptation
Проверка:
> show bfd session extensive
IPv6
Есть несколько способов настраивать BGP между роутерами, работающими с ipv6.
- Прямая ipv6 сессия на ipv6 адресах:
На интерфейсах обычные p2p адреса из /126 (/30) сеточки. Это самый примитивный вариант.
group r7-ipv6 {
type external;
export export-direct;
peer-as 54591;
neighbor fc09:c0:ffee::1;}
Настраиваем сессию на ipv6 адресах в отдельной группе. Если настраивать в группе, в которой настроены также сессии на ipv4-адресах, то сессия на ipv6 поднимется, но роутеры маршрутами обмениваться не будут.
- Сессия на ipv4 адресах, передающая ipv6 префиксы. ipv6 адреса на интерфейсах ipv4-compatible, то есть вида
a-centauri-r5> show configuration interfaces ge-0/0/0.304
description --c32;
vlan-id 304;
family inet {
address 192.168.0.13/30;}
family inet6 {
address ::ffff:192.168.0.13/126;
- сессия строится на ipv4 адресах. в группе или на neighbor настроена передача family inet6 unicast.
a-centauri-r5> show configuration protocols bgp group c31-c32 type external; family inet unicast family inet6 unicast export export-ipv6 peer-as 64514 neighbor 192.168.0.10
- глобально требуется также включить:
a-centauri-r5> show configuration system allow-v4mapped-packets
- Для IPv6 eBGP в рамках VRF нужно указывать routing-instance <> routing-options router-id <>. Иначе сессия не поднимется. Будет прилетать ошибка:
May 21 00:16:05.676938 BGP RECV version 4 as 54591 holdtime 90 id 0.0.0.0 parmlen 30
Либо использовать отдельные lo, который будет выступать в роли router-id для сессии.
- На link-local адресах